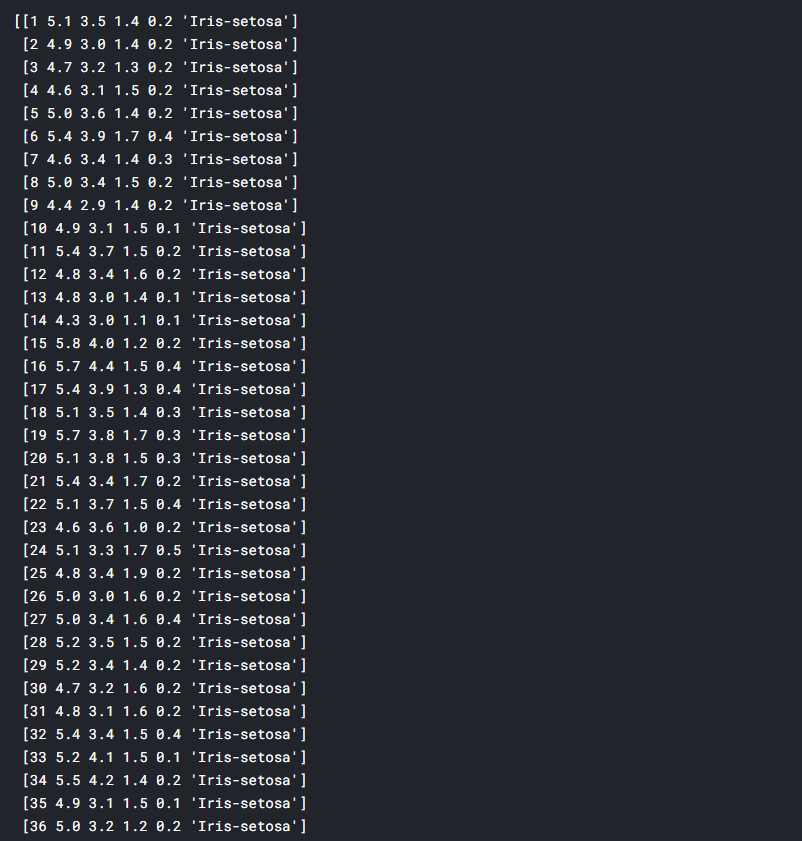
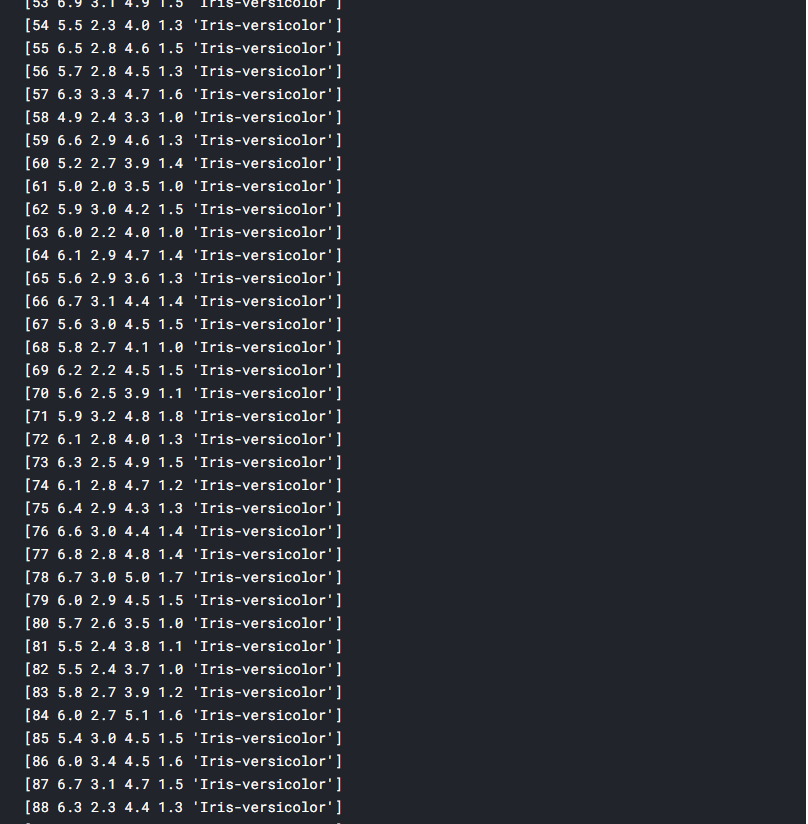
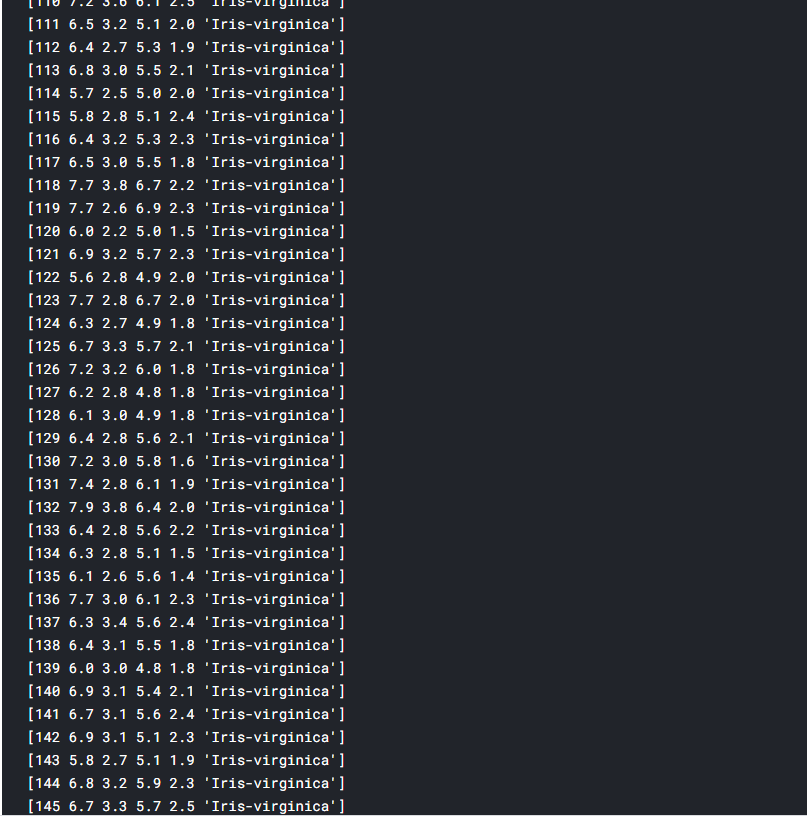
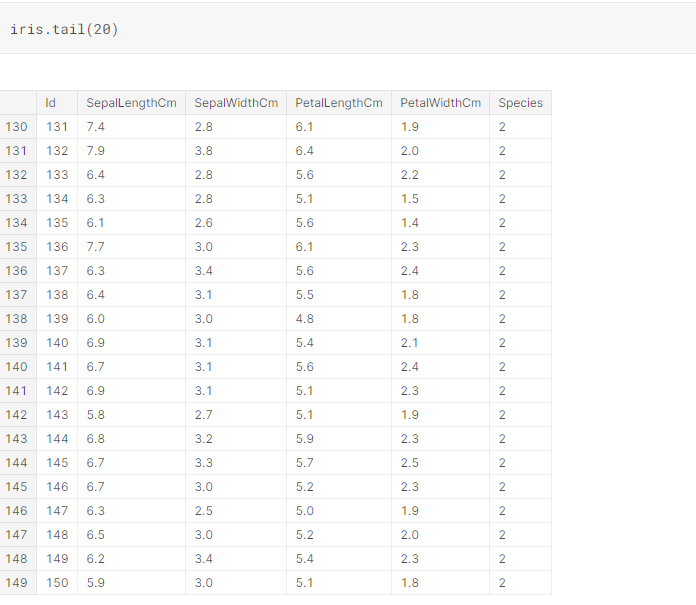
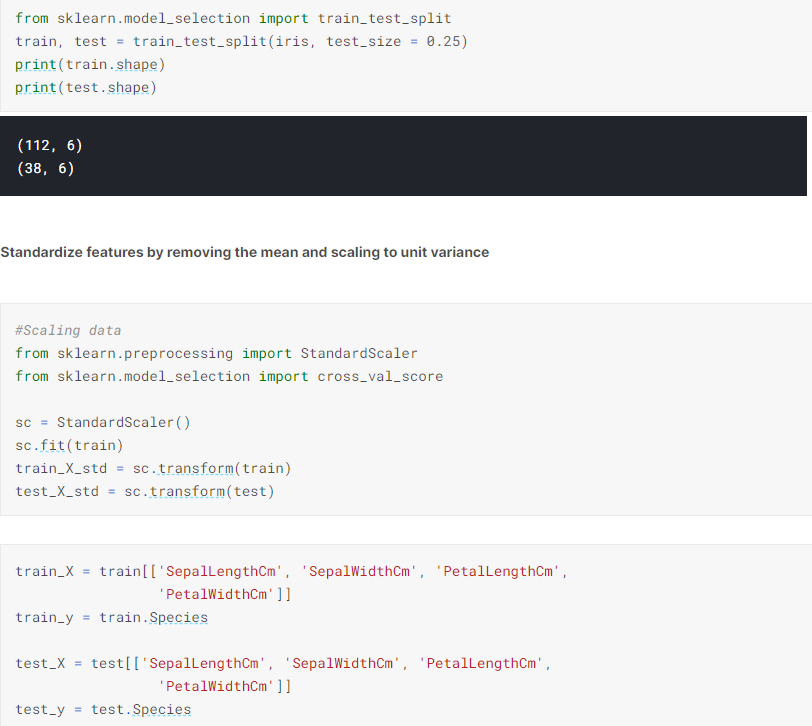
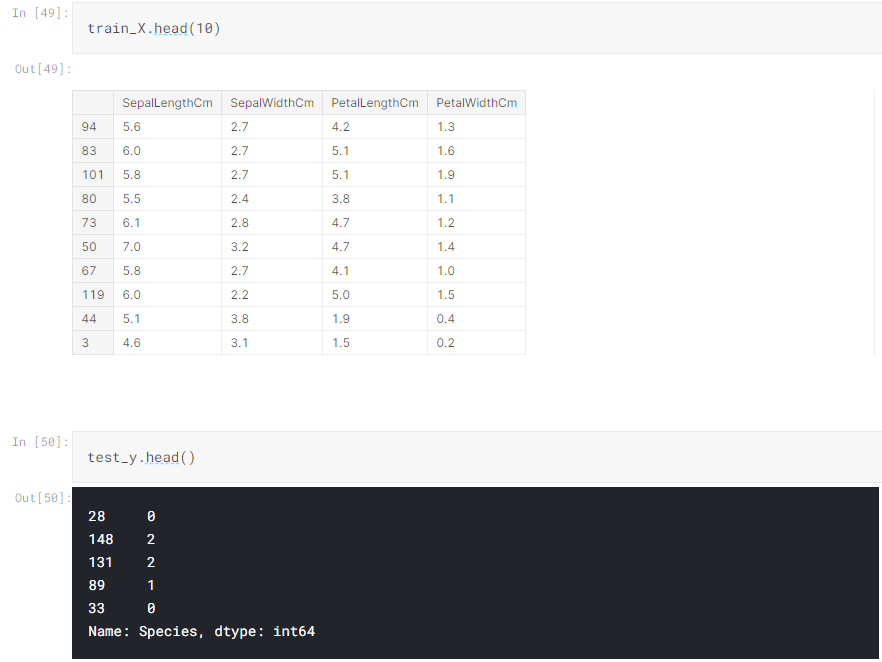
NumPy is a Python library used for working with arrays. It also has functions for working in domain of linear algebra, fourier transform, and matrices. NumPy was created in 2005 by Travis Oliphant. It is an open source project and you can use it freely. NumPy stands for Numerical Python.
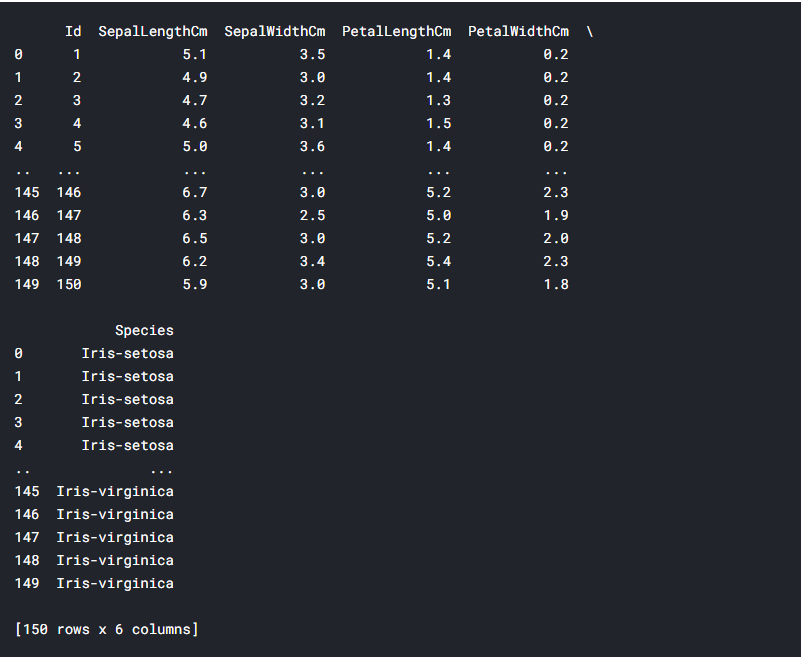
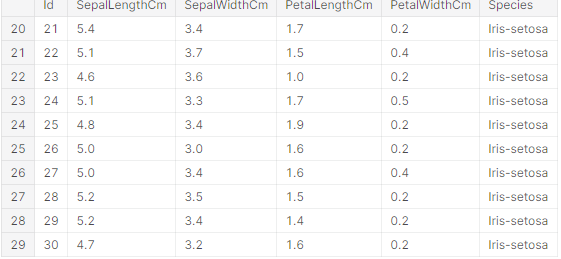
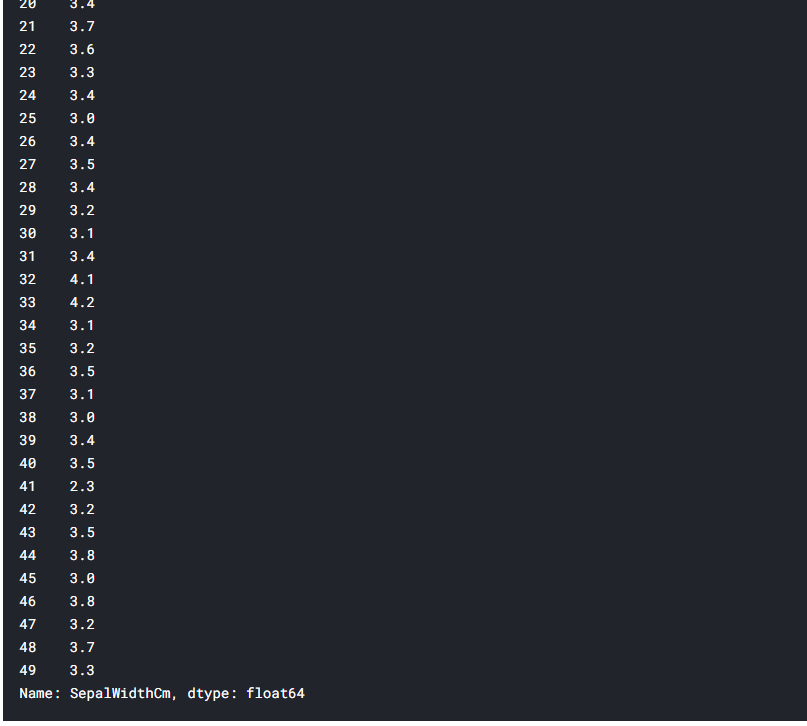
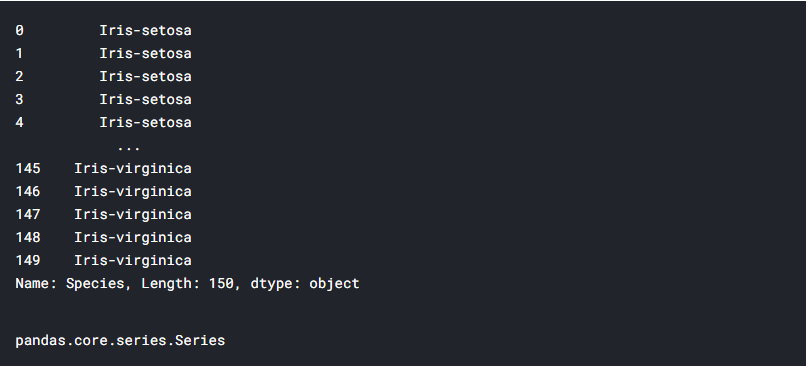
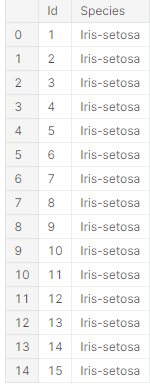
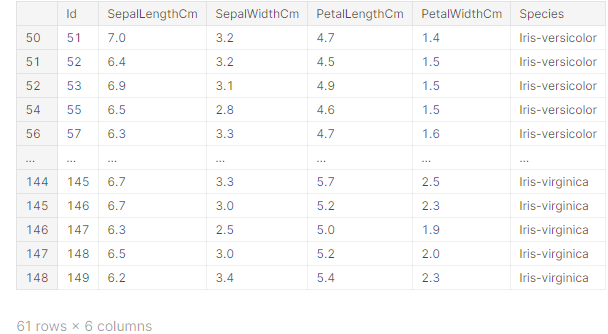
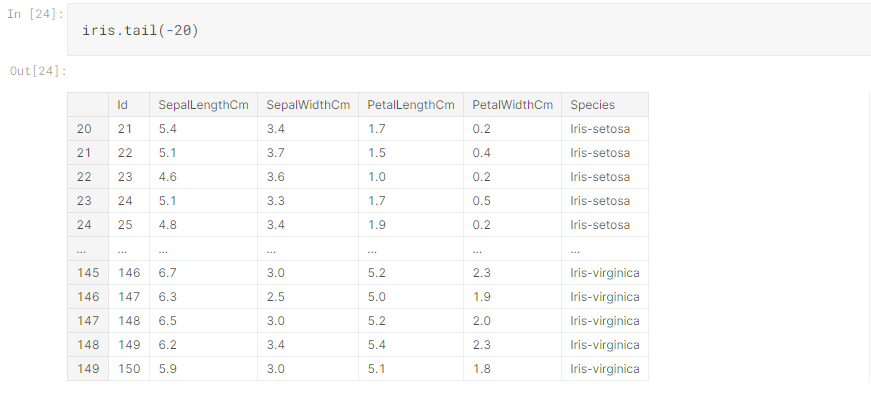
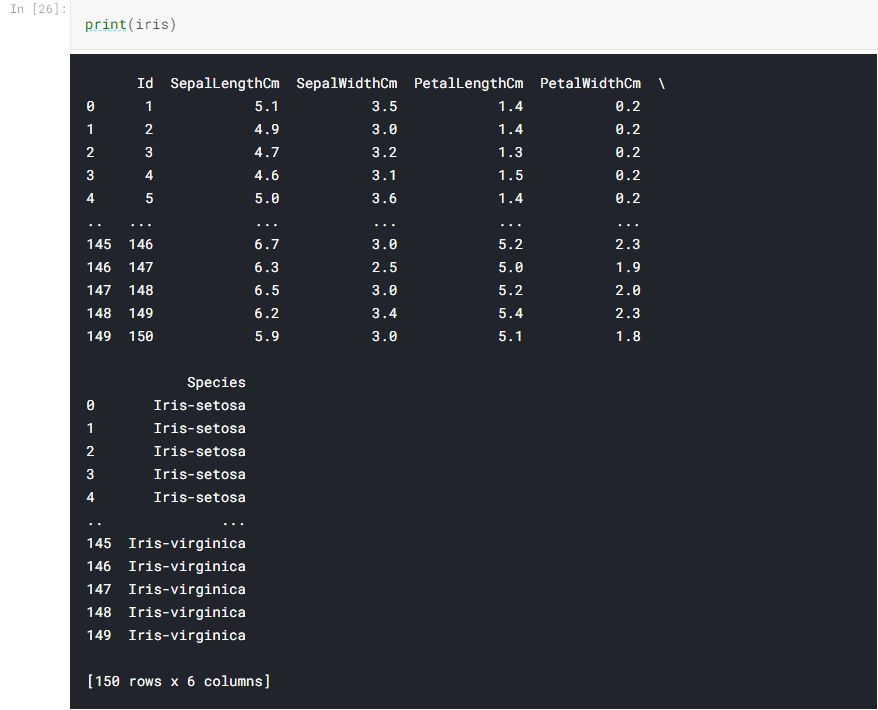
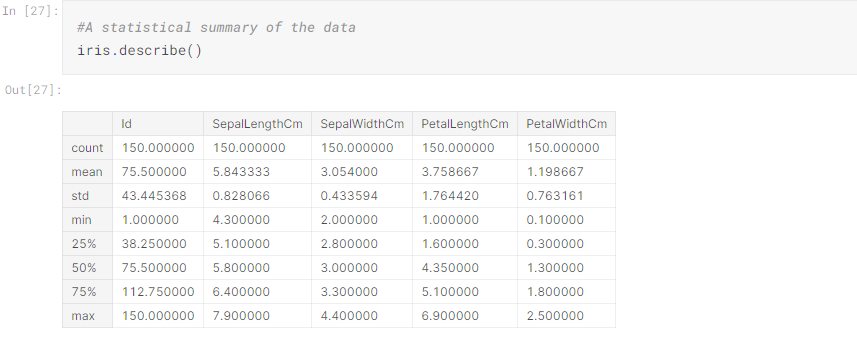
Pandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series. The package is known for a very useful data structure called the pandas DataFrame. Pandas also allows Python developers to easily deal with tabular data (like spreadsheets) within a Python script.